Pourquoi la quantique n’est-elle pas moins locale ?
La non localité traduit la corrélation instantanée entre composantes éloignées d’un système. Cette corrélation à distance, inexistante en mécanique classique, est une des plus grandes bizarreries quantiques. Mais il se trouve que cela pourrait être plus bizarre encore, la mécanique quantique se restreignant finalement à des corrélations mesurées…. Tâchons de comprendre l’explication possible de cette économie.
Commençons par déterminer la limite quantique des corrélations instantanées à distance que permet l’intrication en utilisant l’inégalité CHSH.
Inégalité CHSH
L’inégalité CHSH est la généralisation la plus pratique de l’inégalité de Bell. Elle repose sur le protocole qui suit.
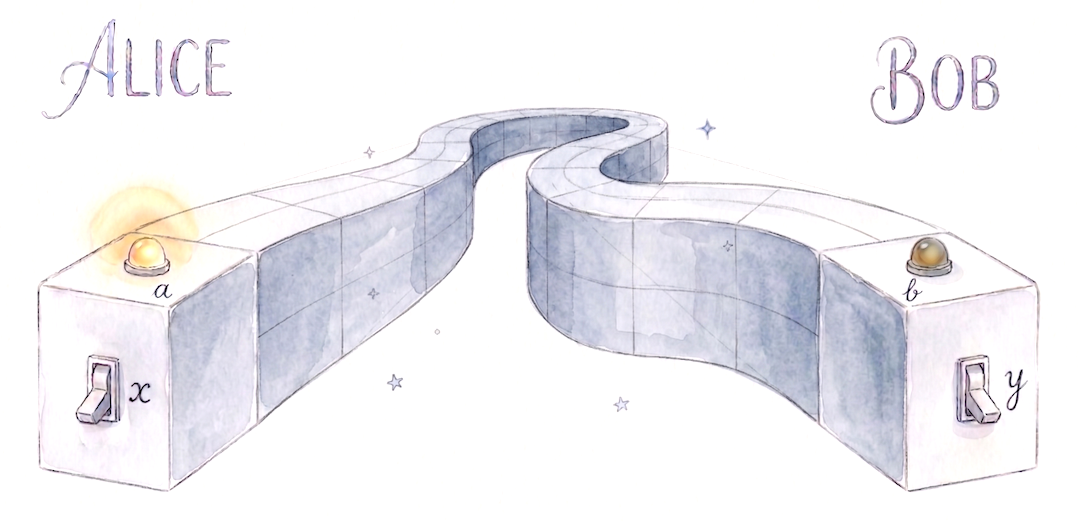
On considère une source qui émet des paires de particules intriquées. L’une est envoyée à Alice, l’autre à Bob.
- Alice peut choisir de mesurer son système selon deux réglages : $a$ ou $a'$ (cela peut être deux angles d'un polariseur pour des photons),
- Bob peut choisir entre les deux réglages $b$ ou $b'$.
Chaque mesure donne un résultat binaire : $+1$ ou $−1$.
On définit la corrélation $E(x,y)$ comme la valeur moyenne du produit des résultats pour les réglages $x$ et $y$ : $E(x, y)=\left\langle A_x \cdot B_y\right\rangle$.
Dans une théorie classique (ou à variables cachées locales), on suppose que le résultat de la mesure d’Alice ne dépend que de son réglage ($a$ ou $a’$), mais absolument pas du choix de Bob.
Considérons la combinaison de mesures suivante pour une paire de particules donnée :
$$ C=a \cdot b+a \cdot b^{\prime}+a^{\prime} \cdot b-a^{\prime} \cdot b^{\prime}=a\left(b+b^{\prime}\right)+a^{\prime}\left(b-b^{\prime}\right) $$
Puisque $b$ et $b’$ valent soit $+1$, soit $−1$ :
- Si $b=b'$, alors $(b+b')=±2$ et $(b-b')=0$. Donc $C=±2$.
- Si $b≠b'$, alors $(b+b')=0$ et $(b-b')=±2$. Donc $C=±2$.
Dans tous les cas, pour chaque particule, la valeur de $C$ est soit $2$, soit $−2$.
On définit alors le paramètre CHSH (initiales de Clauser, Horne, Shimony et Holt) :
$$ S=E(a, b)+E\left(a, b^{\prime}\right)+E\left(a^{\prime}, b\right)-E\left(a^{\prime}, b^{\prime}\right)$$
$S$ est donc la moyenne de $C$ sur un grand nombre de particules. On obtient ainsi l’inégalité CHSH :
$$ |S|\leq 2 $$
Et que prévoit la mécanique quantique ?
Utilisons l’état intriqué singulet : $|\psi\rangle=\frac{1}{\sqrt{2}}(|01\rangle-|10\rangle)$.
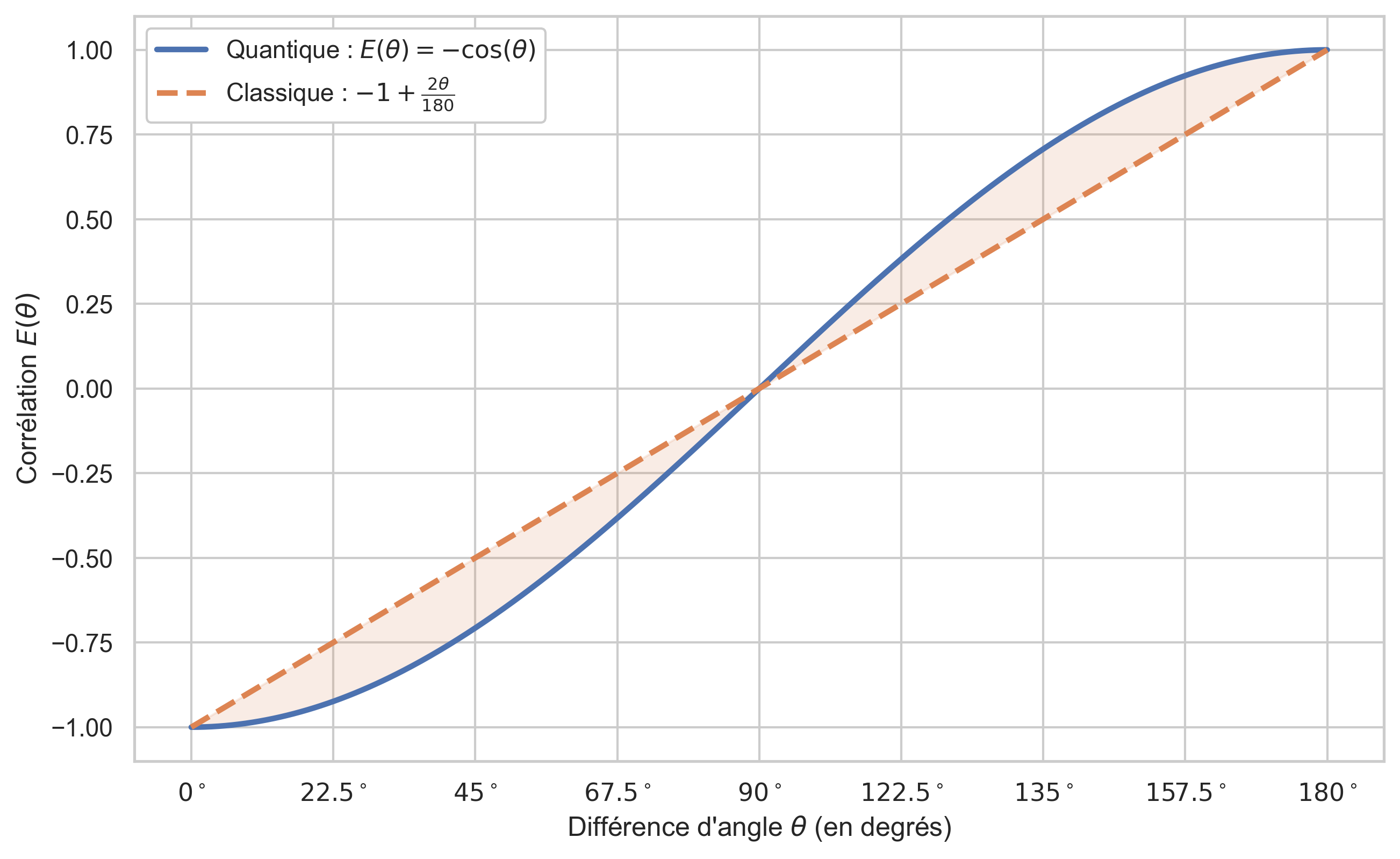
La corrélation quantique entre deux détecteurs orientés avec un angle relatif $\theta$ est $E(\theta)=-\cos (\theta)$ pour cet état.
Pour maximiser $|S|$, Alice et Bob peuvent choisir les angles suivant :
- $a=0°$ et $a'=90°$ pour Alice
- $b=45°$ et $b'=-45°$ pour Bob
Calculons les angles relatifs entre les mesures :
- $\theta(a, b)=45^{\circ} \Longrightarrow E(a, b)=-\cos \left(45^{\circ}\right)=-\frac{\sqrt{2}}{2}$
- $\theta(a, b')=-45^{\circ} \Longrightarrow E(a, b')=-\cos \left(-45^{\circ}\right)=-\frac{\sqrt{2}}{2}$
- $\theta(a', b)=45^{\circ} \Longrightarrow E(a', b)=-\cos \left(45^{\circ}\right)=-\frac{\sqrt{2}}{2}$
- $\theta(a', b')=135^{\circ} \Longrightarrow E(a', b')=-\cos \left(135^{\circ}\right)=+\frac{\sqrt{2}}{2}$
En injectant dans $S$, on obtient :
$|S|=\left| \left(-\frac{\sqrt{2}}{2}\right)+\left(-\frac{\sqrt{2}}{2}\right)+\left(-\frac{\sqrt{2}}{2}\right)-\left(\frac{\sqrt{2}}{2}\right)\right|=4 \times \frac{\sqrt{2}}{2}=2 \sqrt{2}>2$
La mécanique quantique prévoit donc une violation de l’inégalité CHSH. Et c’est bien ce qu’a vérifié les expériences d’Alain Aspect entre autres.
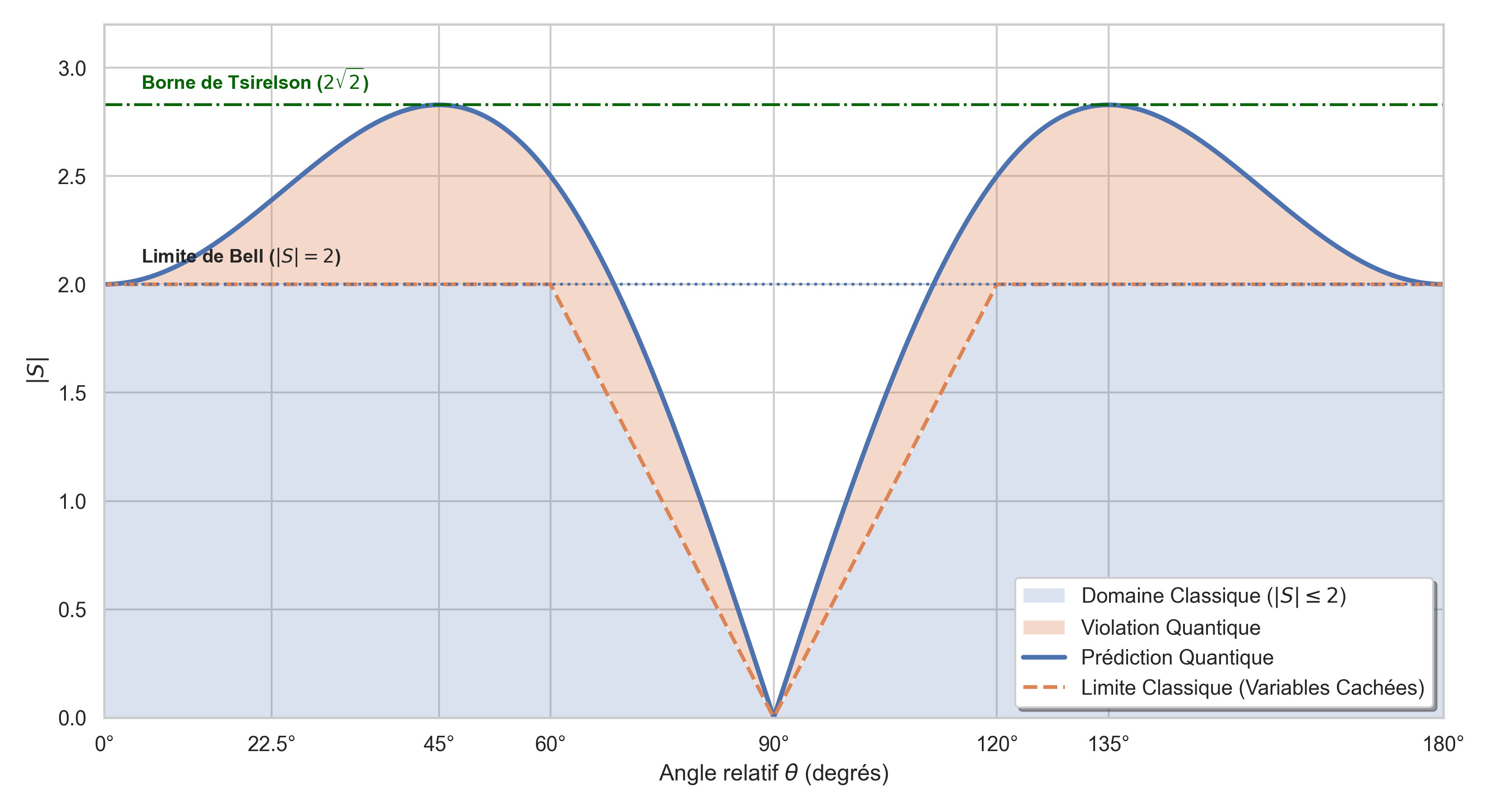
Représentons l’évolution de $|S|$ en fonction de $\theta$ en posant $a=0°$, $b=\theta$, $a’=2\theta$ et $b’=3\theta$.
Cela donne : $|S|=|3 E(\theta)-E(3 \theta)|$
Pour bien comprendre le graphe, on peut déjà se concentrer sur l’allure de l’évolution de la corrélation $E(\theta)$ :
Comme $E(\theta)=-\cos(\theta)$ en quantique pour un état singulet, on obtient $|S|=|3\cos(\theta)-\cos(3\theta)|$. C’est la courbe bleue du premier graphe.
Pour comprendre la partie classique, il faut se pencher sur ce qu’implique un modèle à variable cachée.
Prenons l’exemple où les deux particules sont des disques bicolores peints chacun en rouge et vert de chaque côté d’un diamètre. Le réglage de chaque boîte correspond à l’orientation d’un petit trou qu’on peut tourner à 360°. Le résultat (ce qu’on voit dans le trou) sera bien binaire, soit rouge, soit vert, comme attendu.
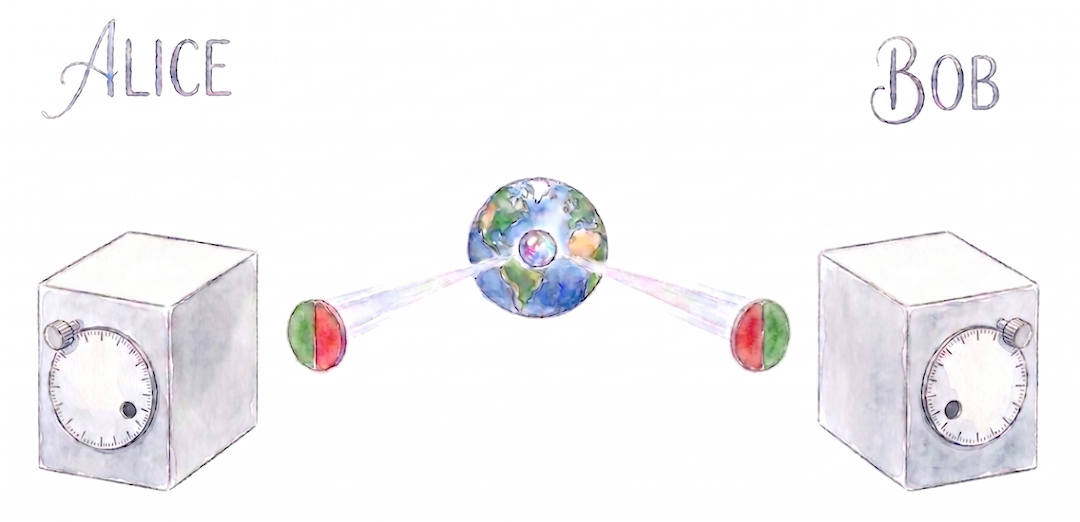
La variable cachée $\lambda$ est ici l’orientation parfaitement opposée des deux disques envoyés à Alice et Bob (opposée pour coller à l’état singulet quantique qui est parfaitement anticorrélé lorsque les réglages sont alignés).
Que vaut alors $E(\theta)$ ? Il s’agit, rappelons-le, de la moyenne des produits des résultats obtenus par Alice et Bob. Cette moyenne est proportionnelle à la probabilité que les deux trous se retrouvent au-dessus du même demi-disque. Et cette probabilité est elle-même proportionnelle à l’écart angulaire entre les deux réglages et passe de $1$ pour $\theta=0°$ à $0$ pour $\theta=180°$. À $\theta=0°$, la corrélation vaut donc $-1$ et elle vaut $1$ pour $\theta=180°$ en passant par $0$ à $\theta=90°$.
Cela donne une corrélation évoluant linéairement : $E(\theta)=-1+\frac{2\theta}{180}$ pour $\theta\in[0°,180°]$. Et par symétrie, $E(\theta)=1-\frac{2\theta}{180}$ pour $\theta\in[180°,360°]$. Par conséquent, la pente de $E(3\theta)$ change deux fois de signes entre $0°$ et $180°$ : elle croît sur $[0°,60°]$, décroît sur $[60°,120°]$ (car on a alors $3\theta \in [180°,360°]$), puis croît à nouveau sur $[120°,180°]$. Cela explique l’allure bizarre de la courbe classique sur le graphe $|S(\theta)|$.
Borne de Tsirelson
D’où vient la borne supérieure de $2\sqrt{2}$ ? Est-elle indépassable ? En quantique, oui ! Montrons pourquoi.
Construisons l’opérateur de Bell $\mathcal{B}$ à partir des observables d’Alice $(A, A’)$ et de Bob $(B,B’)$ :
$$\mathcal{B}=A \otimes B+A \otimes B’+A’ \otimes B-A’ \otimes B’$$
On a alors $S=\langle\psi| \mathcal{B}|\psi\rangle$.
Or on peut montrer que $\mathcal{B}^2=4 I+\left[A, A^{\prime}\right]\otimes \left[B^{\prime}, B\right]$.
Cela permet déjà de constater que si les opérateurs commutent, on retombe sur la limite classique de $2$ ($4$ pour $S^2$).
Pour dépasser $2$, les opérateurs d’Alice (et ceux de Bob) ne doivent pas commuter. Et la valeur maximale est atteinte quand les commutateurs sont maximaux, ce qui correspond géométriquement à des bases de mesure à 90° l’une de l’autre (bases complémentaires).
On peut écrire les observables d’Alice et Bob en fonction des matrices de Pauli (les seules réponses possibles étant $-1$ ou $+1$, ils mesurent un système à deux niveaux, donc un qubit) :
$A=a\cdot \sigma$ et $A’=a’\cdot \sigma$ où $a$ et $a’$ sont les vecteurs unitaires correspondant aux orientations de la boîte d’Alice et $\sigma=\left(\sigma_x, \sigma_y, \sigma_z\right)$ se décompose sur les axes de référence de la boîte.
Et comme $\left[\sigma_i, \sigma_j\right]=2 i \epsilon_{i j k} \sigma_k$, on a $\left[A, A^{\prime}\right]=2 i\left(a \wedge a^{\prime}\right) \cdot \sigma$.
Le vecteur $a\wedge a’$ a une norme égale à $\sin(\theta)$, où $\theta$ est l’angle entre les deux réglages. Cette norme est maximale ($=1$) quand Alice choisit des réglages orthogonaux ($a\perp a’$). Dans ce cas, $\left[A, A^{\prime}\right]=2 i \sigma_n$ où $\sigma_n$ est la matrice de Pauli dans la direction normale au plan de mesure $(a,a’)$. Les valeurs propres de $\sigma_n$ étant $\{+1,-1\}$, les valeurs propres de $[A,A’]$ sont $\{+2\mathrm{i},-2\mathrm{i}\}$. La norme du commutateur (plus grande valeur propre en valeur absolue) est $2$.
Le raisonnement est exactement le même pour Bob. S’il choisit ses réglages $b$ et $b’$ orthogonaux, son commutateur $[B’,B]$ aura également pour valeurs propres $\{+2\mathrm{i},-2\mathrm{i}\}$.
Regardons maintenant l’opérateur global dans l’espace produit $\mathcal{H}_A\otimes \mathcal{H}_B$ : $\left[A, A^{\prime}\right] \otimes\left[B^{\prime}, B\right]$.
- $(2 i) \times(2 i)=-4$
- $(2 i) \times(-2 i)=-4$
- $(-2 i) \times(2 i)=-4$
- $(-2 i) \times(-2 i)=-4$
La valeur propre maximale de ce terme de corrélation est donc $4$ et les valeurs propres maximales de $\mathcal{B}^2$ sont alors $4+4=8$.
On en conclut que $S^2≤8$ ce qui nous donne la valeur maximale de l’inégalité CHSH permise par la quantique :
C’est la borne de Tsirelson.
Ce plafond quantique a une origine géométrique liée à la nature vectorielle des états quantiques. Pour obtenir plus, il faudrait qu’un vecteur puisse s’aligner avec deux directions orthogonales en même temps… Plus on veut qu’un état quantique soit porteur d’une information $a$, moins il peut être porteur d’une information $b$ si les opérateurs associés à $A$ et $B$ ne commutent pas.
Et hors des lois quantiques, la borne de Tsirelson reste-t-elle indépassable ? Non.
Boites PR : corrélation maximale
On s’affranchit maintenant de tout espace vectoriel et autres contraintes de norme pour ne plus s’occuper que de logique.
Retournons à la définition de $S$ : $E(a, b)+E\left(a, b^{\prime}\right)+E\left(a^{\prime}, b\right)-E\left(a^{\prime}, b^{\prime}\right)$.
Comme chaque corrélation $E$ est comprise entre $-1$ et $1$, le maximum théorique de $S$ est $4$ avec $E(a,b)=E(a’,b)=E(a,b’)=±1$ et $E(a’,b’)=\mp 1$.
Mais peut-on atteindre ce maximum sans communication entre Alice et Bob ? Pour cela, il faut que les observations locales d’Alice (ses statistiques de résultats) ne dépendent pas des choix de réglage fait par Bob à l’autre bout de l’univers (et vice versa). Dit autrement, Alice ne doit pas savoir quel réglage Bob a choisi en regardant ses résultats.
On va y parvenir à l’aide d’une boîte PR (pour Popescu et Rohrlich).
Une boîte PR est un système bipartite théorique. Alice et Bob entrent chacun un bit ($x$ pour Alice, $y$ pour Bob) et reçoivent chacun un bit en sortie ($a$ pour Alice, $b$ pour Bob). La boîte garantit contractuellement que les sorties respectent toujours l’équation :
Où $\oplus$ est le XOR logique (addition modulo 2).
Montrons d’abord que cette boîte est bien non signalante.
Imaginons par exemple que Bob entre la valeur $0$ et Alice entre la valeur $1$ dans leurs parties respectives de la boite. Alors la boîte pourra fournir $1$ aux deux ou $0$ aux deux ($x\cdot y = 0\cdot 1 = 0$ et donc la boîte impose $a\oplus b = 0$, ce qui implique que $a$ et $b$ soient identiques). Par conséquent, Alice a $50\%$ de chance de recevoir un $0$ et $50\%$ de recevoir un $1$. Et cela restera le cas quel que soit le réglage de Bob (la marginale d’Alice1 vaut $50\%$), ce qui empêche Alice d’inférer quoi que ce soit sur son réglage ; on a bien non signalisation.
Calculons la valeur de $S$ à partir des valeurs des mesures $a$ et $b$.
- Si $a\oplus b = 0$, alors $a=b$. Les résultats sont identiques et la corrélation vaut donc $+1$.
- Si $a\oplus b = 1$, alors $a≠b$. Les résultats sont opposés et la corrélation vaut donc $-1$.
La corrélation $E(x,y)$ vaut par définition la moyenne des produits des résultats. Mais comme la boîte PR est déterministe dans ses corrélations, $E(x,y)$ vaut soit $+1$, soit $-1$.
Les couples de réglages possibles pour Alice et Bob sont $(0,0)$, $(0,1)$, $(1,0)$ et $(1,1)$. D’où $S=E(0,0)+E(0,1)+E(1,0)-E(1,1)$.
Appliquons la règle $a \oplus b=x \cdot y$ pour chaque couple de réglage :
- Pour $(x,y)=(0,0)$ : $a\oplus b=0\cdot 0 = 0\Longrightarrow E(0,0)=1$.
- Pour $(x,y)=(0,1)$ : $a\oplus b=0\cdot 1 = 0\Longrightarrow E(0,1)=1$.
- Pour $(x,y)=(1,0)$ : $a\oplus b=1\cdot 0 = 0\Longrightarrow E(1,0)=1$.
- Pour $(x,y)=(1,1)$ : $a\oplus b=1\cdot 1 = 1\Longrightarrow E(1,1)=-1$.
Résultat :
On a bien atteint le plafond algébrique tout en respectant la contrainte de non-signalisation.
Dans le diagramme suivant, on projette l’espace des corrélations (de dimension 8 pour le scénario CHSH) sur un plan 2D, $S’$ représente une combinaison linéaire des fonctions de corrélation différente de $S$ (avec le signe “moins” placé différemment).
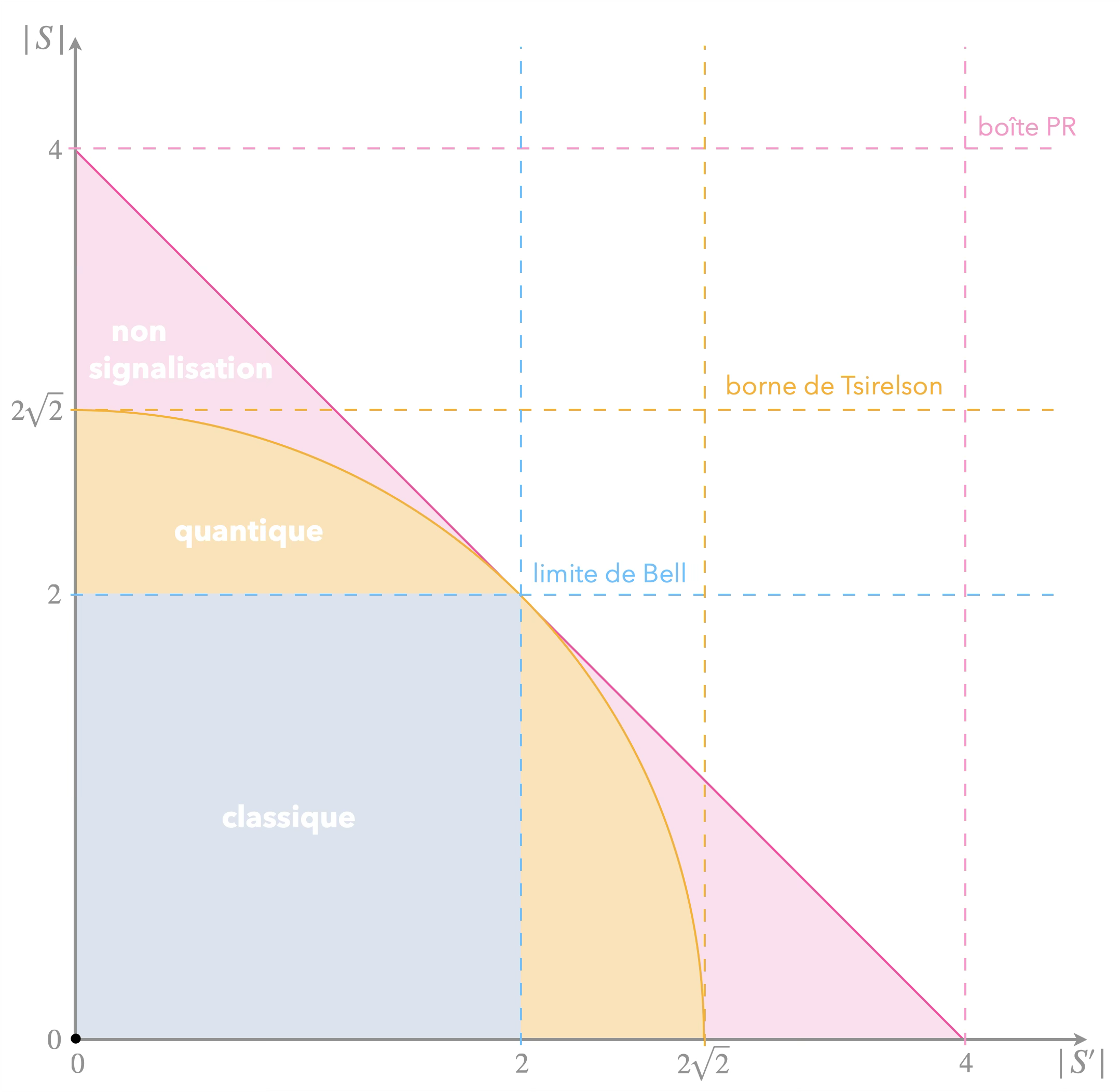
Pourquoi la nature se restreint-elle à la borne de Tsirelson alors qu’il y a de la place plus haut tout en continuant de respecter l’interdiction de communiquer plus vite que la lumière ? Quitte à être non locale, pourquoi ne pas l’être complètement ?
Une réponse plutôt convaincante se cache dans le monde de l’information.
Transfert d’information
Ça commence par un jeu de devinettes entre Alice et Bob.
Supposons qu’Alice ait deux bits $x_0$ et $x_1$. Elle envoie classiquement un bit unique $m$ à Bob (qu’elle intrique comme elle le souhaite avec les deux bits qu’elle possède). Bob doit alors essayer de deviner l’un des deux bits d’Alice (celui de son choix).
La probabilité de succès pour Bob mesure donc la capacité d’Alice a faire tenir deux bits d’information sur un seul bit envoyé.
Alice et Bob partagent à nouveau un système bipartite (que cela soit un état quantique intriqué, une boîte PR, ou autre) qu’on va appeler génériquement boîte non-signalante (les réponses de la boîte de Bob n’informent pas sur les réglages et réponses de la boîte d’Alice).
Ils suivent le protocole suivant :
- Alice utilise le réglage $X=x_0\oplus x_1$ sur sa boîte et obtient $a\in \{{0,1\}}$
- Elle envoie $m=x_0\oplus a$ à Bob.
- Bob veut $x_k$, il mesure avec le réglage $Y=k$ et obtient $b\in \{{0,1\}}$.
- Son estimation est $g=m\oplus b$.
L’estimation de Bob est bonne si :
- Lorsque $k=0$, $x_0 \oplus a \oplus b=x_0$. Donc si $a\oplus b = 0$.
- Lorsque $k=1$, $x_0 \oplus a \oplus b=x_1$. Donc si $a\oplus b=x_0\oplus x_1$.
Dans les deux cas, la condition de succès peut s’écrire :
On retrouve la règle donnant une valeur maximale à $S$ !
Comme la corrélation physique entre $X$ et $Y$ vaut :
$$E(X, Y)=(+1) \cdot P(a=b)+(-1) \cdot P(a≠b)$$
On peut la réécrire :
$$E(X, Y)=P(a\oplus b=0) - P(a\oplus b =1)$$
Et comme $P(a \oplus b=0)+P(a \oplus b=1)=1$, on a :
$$ \begin{aligned} P(a \oplus b=0)&=\frac{1+E(X, Y)}{2}\\ P(a \oplus b=1)&=\frac{1-E(X, Y)}{2} \end{aligned} $$
La probabilité de succès $P$ est la moyenne des probabilités de gagner sur les 4 configurations possibles de $(X,Y)$ :
$$ P=\frac{1}{4}\left[P_{\text {succès }}(0,0)+P_{\text {succès }}(0,1)+P_{\text {succès }}(1,0)+P_{\text {succès }}(1,1)\right] $$
En utilisant la condition $a\oplus b = X\cdot Y$, on obtient :
- Pour $(0,0)$, $(0,1)$ et $(1,0)$, on gagne si $a\oplus b = 0$. La proba est $P(a \oplus b=0)=\frac{1+E(X, Y)}{2}$
- Pour $(1,1)$, on gagne si $a\oplus b = 1$. La proba est $P(a \oplus b=1)=\frac{1-E(X, Y)}{2}$
En remplaçant dans $P$ :
$$ \begin{aligned} P&=\frac{1}{4}\left[\frac{1+E_{00}}{2}+\frac{1+E_{01}}{2}+\frac{1+E_{10}}{2}+\frac{1-E_{11}}{2}\right]\\ &=\frac{1}{8}\left[4+\left(E_{00}+E_{01}+E_{10}-E_{11}\right)\right] \end{aligned} $$
On reconnaît l’expression de $S$ dans la parenthèse et finalement :
- En classique ($S=2$), $P=\frac34$. Bob est totalement informé sur un des deux bits, mais quand il veut l'autre, il n'a qu'une chance sur deux de succès. Toute l'info que lui envoie Alice est concentrée sur un des deux bits.
- En quantique ($S=2\sqrt{2}$), $P\approx 85\%%$. Bob améliore ses chances par rapport à la situation classique car l'information envoyée par Alice concerne maintenant les deux bits à la fois.
- Avec une boîte PR ($S=4$), $P=1$. Bob connaît $x_0$ et $x_1$ avec certitude dès qu'il reçoit le bit $m$.
C’est bien beau, mais on n’a toujours pas d’explication à la modération quantique vis-à-vis de la force de ses corrélations.
C’est là qu’entre en jeu un nouveau principe.
Le principe de causalité informationnelle
Le principe de causalité informationnelle (CI) stipule que :
Dans notre petit jeu, Bob ne peut deviner au mieux qu’un bit d’Alice selon ce principe, même si le bit $m$ envoyé par Alice est corrélé (quantiquement intriqué par exemple) à ses autres bits. Ça paraît somme toute assez raisonnable… Mais on verra dans la suite que les possibles conséquences de sa violation finissent de convaincre de son bien fondé.
Pour l’exprimer mathématiquement, on utilise l’information mutuelle $I$ qui mesure la réduction d’incertitude, c’est-à-dire l’information gagnée. Pour un bit dont on devine la valeur avec une probabilité $P$, l’information gagnée est : $I=1-H(P)$ où $H(P)$ est l’entropie binaire.
1 bit
Si on devine au pif complet, $P=\frac12\Rightarrow H(P)=1\Rightarrow I=0$, on obtient une information nulle. Logique.
Si on est sûr, $P=1 \Rightarrow H(P)=0 \Rightarrow I=1$. Logique encore, on a bien 1 bit d’information en notre possession.
2 bits
Pour deux bits $x_0$ et $x_1$, le principe de CI impose que la somme des informations que Bob peut extraire sur chacun ne dépasse pas la taille du message envoyé ($|m|=1$ bit) :
$$I(x_0)+I(x_1)≤1$$
Dans le cas classique, on a vu qu’en moyenne, Bob a $P=75\%$ de chance de deviner le bit choisi. Pour chaque bit, on a donc : $H(P)=-\frac{1}{\ln 2}\left(P\ln P+ (1-P)\ln(1-P)\right)\approx 0,81 \Longrightarrow I(x_k)\approx 0,19$. Et donc : $I=I(x_0)+I(x_1) \approx 0,38$. On est large inférieur à $1$.
Dans le cas quantique, $P$ grimpe à $85\%$, ce qui tire l’information mutuelle sur un bit à $0,40$ et donc l’information mutuelle totale à $0,80$, toujours inférieure à $1$.
Et qu’obtiendrait-on si Alice et Bob utilise des boîtes PR ?
Dans ce cas, $P=100\%$. L’information mutuelle pour un bit deviné avec certitude est $I=1$.
Pour les deux bits, on obtient : $I=I(x_0)+I(x_1)=2>1$.
Bob a extrait 2 bits d’information alors qu’Alice n’en a envoyé qu’un seul. 1 bit a donc transporté 2 bits d’information 😳
Mais pour obtenir précisément le point de rupture où le degré de corrélation devient trop grand pour que le principe de CI soit respecté, il faut garnir davantage la base de données d’Alice.
4 bits
Supposons qu’Alice ait maintenant 4 bits ($x_0,x_1,x_2,x_3$) à faire deviner à Bob en lui envoyant un seul bit. Pour fabriquer le bit à envoyer, Alice va procéder par concaténations successives grâce à une structure en pyramide sur deux niveaux :
- Niveau 1 : Elle utilise une première boîte sur $(x_0,x_1)$ qui produit un message $m_0$, et et une deuxième boîte sur $(x_2,x_3)$ qui produit $m_1$.
- Niveau 2 : Elle utilise une troisième boîte sur ces messages intermédiaires $(m_0,m_1)$ pour produire le message final $m$ qu'elle envoie à Bob.
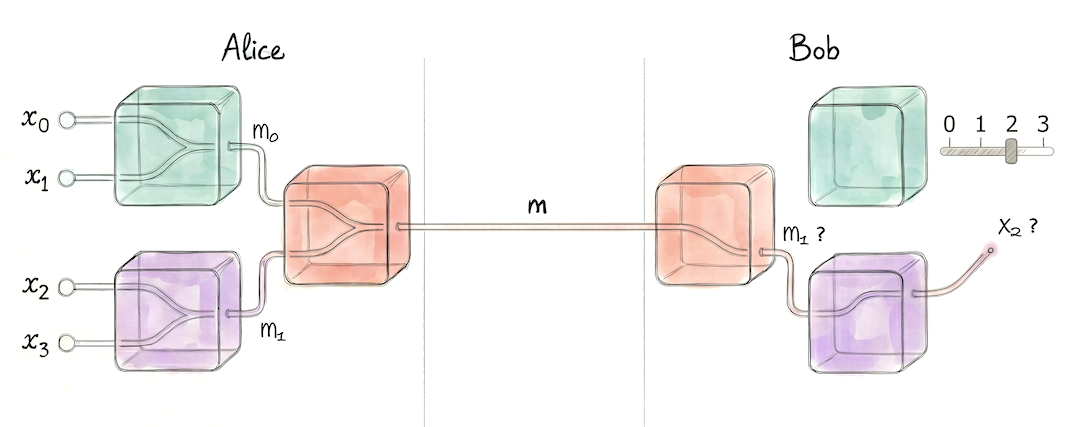
Alice parvient ainsi à corréler le bit $m$ aux 4 bits qu’elle possède.
Bob possède 3 boîtes appariées aux 3 boîtes d’Alice.
S’il veut connaître le bit $x_2$, il doit d’abord utiliser sa boîte de niveau 2 pour essayer de décoder $m_1$ à partir de $m$. Sa probabilité de succès est $P$. Puis il lui faudra décoder $x_2$ à partir de $m_1$ grâce à sa deuxième boîte du niveau 1. La probabilité de succès est à nouveau $P$.
Il réussit à déterminer $x_2$ si :
- Il ne fait aucune erreur aux deux étapes $\Longrightarrow$ probabilité $P\times P$.
- Il fait une erreur à chaque étape (les deux erreurs se compensant en binaire) $\Longrightarrow$ probabilité $(1-P)\times(1-P)$.
La probabilité $P_2$ pour Bob de deviner avec succès un des 4 bits d’Alice est donc :
$$P_2=P^2+(1-P)^2=2 P^2-2 P+1$$
Calculons maintenant le double du biais $\epsilon_2$ défini comme l’écart au hasard pur :
$$ 2 \epsilon_2 = 2\left(P_2-\frac12\right)=2P_2-1=2\left(2 P^2-2 P+1\right)-1=4 P^2-4 P+1=(2 P-1)^2 $$
n bits
Généralisation à $N=2^n$ bits : si on répète cette pyramide sur $n$ niveaux, par récurrence, le biais après $n$ étapes devient :
$$2\epsilon_n = \left(2 P_n-1\right)=(2 P-1)^n$$
Rappelons-nous de la relation entre $P$ et $S$ : $P=\frac{1}{2}\left(1+\frac{S}{4}\right)$. On obtient alors :
$$2 P_n-1=\left(\frac{S}{4}\right)^n$$
Lien entre information et probabilité
On a vu que l’information mutuelle entre un bit d’Alice et l’estimation de Bob est $I(P)=1-H(P)$.
Si $n$ est grand, on peut se dire que l’estimation de Bob pour un de ces $n$ bits sera proche du pur hasard. Faisons alors un développement limité de $H(P)=-\frac{1}{\ln(2)}\left[ P\ln(P)+(1-P)\ln(1-P)\right]$ autour de $P=\frac12$. On pose $P=\frac12 + \epsilon$.
$$H(1 / 2+\epsilon) \approx 1-\frac{2}{\ln 2} \epsilon^2$$
L’information mutuelle est donc :
$$ I(P)=1-H(P) \approx \frac{2}{\ln 2} \epsilon^2=\frac{1}{2 \ln 2}(2 P-1)^2 $$
Retour à la causalité informationnelle
Le principe de CI stipule que pour $N$ bits, la somme de l’information extraite par Bob ne peut pas dépasser le message envoyé (1 bit) :
$$\sum_{i=1}^{2^n} I\left(x_i\right) \leq 1$$
Puisque tous les bits sont symétriques dans la pyramide :
$$ \begin{aligned} 2^n \cdot I\left(P_n\right) &\leq 1\\ 2^n \cdot \frac{1}{2 \ln 2}\left(2 P_n-1\right)^2 &\leq 1\\ \frac{1}{2 \ln 2} 2^n\left[(2 P-1)^n\right]^2 &\leq 1\\ \frac{1}{2 \ln 2}\left[2 \cdot(2 P-1)^2\right]^n &\leq 1 \end{aligned} $$
Cette inégalité doit être respectée pour n’importe quelle valeur de $n$. Or si le terme entre crochets est supérieur à 1, l’expression diverge quand $n\to \infty$, et finira donc fatalement par violer l’inégalité. Cela force la contrainte suivante :
$$ \begin{aligned} 2 \cdot(2 P-1)^2 &\leq 1\\ (2 P-1)^2 &\leq \frac{1}{2} \end{aligned} $$
Utilisons $P=\frac 12 \left(1+\frac S 4\right)\Longrightarrow(2P−1)=\frac S 4$ pour obtenir :
$$\left(\frac{S}{4}\right)^2 \leq \frac{1}{2}$$
Et finalement :
On a retrouvé la borne de Tsirelson 🥳
- Si $S<2\sqrt{2}$, l'efficacité de la transmission d'information décroît plus vite que le nombre de bits n'augmente. La somme totale reste "écrasée" sous la barre de 1 bit, même si Alice a des milliards de bits.
- Si $S>2\sqrt{2}$, l'efficacité de la corrélation devient suffisamment forte pour que l'augmentation du nombre de bits finisse par permettre à Bob de deviner plus d'un seul bit. Et le nombre de bits qu'il devinera sans se tromper tendra même vers l'infini... Bob finit par posséder une information infinie sur les bits d'Alice en n'ayant reçu qu'un seul bit !
Un univers où $S>2\sqrt{2}$ est un univers où la communication classique est “trop efficace” au point de briser la logique même de ce qu’est un bit (un seul bit pourrait y transporter 100 Go d’information par exemple).
La mécanique quantique se cale exactement sur la valeur qui sature cette limite sans la dépasser.
Le principe que suit la nature est peut être alors : un bit contient toujours exactement un bit d’information, pas plus, mais pas moins non plus.
Dans un univers réel où un système quantique n’est en effet jamais parfaitement isolé mais plus ou moins intriqué avec tous les autres systèmes quantiques, un bit contient toujours des multitudes qui se réduisent finalement à un bit d’information par funambulisme sur la frontière de Tsirelson.
On peut remarquer aussi que le théorème de non-clonage est fortement lié au respect du principe de CI. En empêchant de contourner l’incertitude de la mesure2, on évite en effet de retirer trop d’information du message d’Alice.
Le principe de causalité informationnelle et son utilisation pour retrouver la borne de Tsirelson sont des découvertes étonnamment récentes puisque cela date d’un article de 2009 de Pawłowski et al dans Nature intitulé Information Causality as a Physical Principle.
-
Pour un système complexe avec plusieurs acteurs (comme Alice et Bob), la marginale est ce qu’un seul acteur voit “dans son coin”, sans tenir compte des résultats de l’autre.
Soit deux variables aléatoires discrètes $X$ et $Y$ dont la loi de probabilité jointe est donnée par $P(X,Y)$.
La loi marginale de $X$, notée $P(X)$, est obtenue en sommant les probabilités jointes sur toutes les valeurs possibles de $Y$ :
$P(X=x)=\sum_y P(X=x, Y=y)$
Et de même, la marginale de $Y$ est :
$P(Y=y)=\sum_x P(X=x, Y=y)$
On utilise le terme « marginale » car, historiquement, ces valeurs étaient calculées dans les marges des tableaux de contingence. ↩︎ -
La mesure détruit ce qui n’est pas cherché. La mesure d’un qubit sur $X$ rend inaccessible l’information sur $Y$ par exemple. Mais avec une batterie de clones, on peut tout chercher à la fois. Et ces statistiques nous informeraient aussi entièrement sur les réglages d’Alice lors de sa mesure. Le théorème de non-clonage protège donc le non-signalement. ↩︎